Redis数据结构-SkipList
在《Redis数据结构》中我们说到Redis的Soted Set类型底层使用的是
ziplist以及skiplist,然后在Redis7.0的时候正式使用listpack替换了ziplist,本文主要简单说下skiplist,观关于ziplist以及listpack可以看看《Redis数据结构-ZipList与ListPack》这篇文章。
什么时候使用skiplist
在Redis中只有Sorted Set使用到了
skiplist。skiplist在查找、删除、添加等操作的时间复杂度都是O(log2N),这就是跳跃表的优点,其缺点就是需要的存储空间比较大,属于用空间换时间的类型。
在Redis的配置文件中我们可以看到这么两个配置:
# 与Hash以及List类型类似,为了节省大量空间,
# Sorted Set在存储时也会被特殊编码。这种编码仅在Sorted Set的长度和元素低于以下限制时使用:
# ==============================Redis6.0==============================
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
# ==============================Redis7.0==============================
zset-max-listpack-entries 128
zset-max-listpack-value 64
这里使用Redis7.0来测试,首先将配置zset-max-listpack-entries改小一点方便测试,这里我们改成3:
127.0.0.1:6379> CONFIG SET zset-max-listpack-entries 3
OK
127.0.0.1:6379> ZADD zset1 1 a 2 b 3 c
(integer) 3
127.0.0.1:6379> OBJECT ENCODING zset1
"listpack"
127.0.0.1:6379> ZADD zset1 4 d
(integer) 1
127.0.0.1:6379> OBJECT ENCODING zset1
"skiplist"
可以看到这里元素数量超过3后,编码方式就从listpack变成了skiplist,然后我们再将配置zset-max-listpack-value改成5:
127.0.0.1:6379> CONFIG SET zset-max-listpack-value 5
OK
127.0.0.1:6379> ZADD zset2 1 a
(integer) 1
127.0.0.1:6379> OBJECT ENCODING zset2
"listpack"
127.0.0.1:6379> ZADD zset2 1 abcdefg
(integer) 1
127.0.0.1:6379> OBJECT ENCODING zset2
"skiplist"
同理当我们添加的元素长度超过5后,编码方式也会从从listpack变成了skiplist。
skiplist是什么
单向链表
首先我们先来看一个单向链表,即使这个链表中的数据都是有序的,但是当我们想要查找某一个数据的时候,也只能遍历这个链表,时间复杂度是O(n),比如在下面这个链表中,想要查找39,则需要遍历8次才行。

我们都知道数组以及链表它们都有自己的优缺点,那有没有办法搞一种数据结构,使得链表的遍历也能快呢?
既然链表遍历慢,时间复杂度是O(n),那尝试给链表加个索引是否能变快呢?这里将上面的链表稍微改造一下,我们在每个节点上新增一个指针down,并且垂直扩充链表,最后可以得到下面这样一个数据结构:
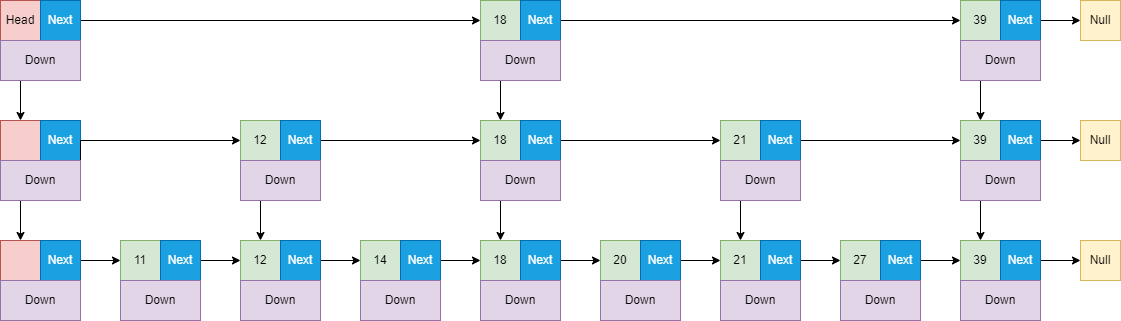
这样就相当于增加一个“捷径”(多级索引),减少了遍历的次数,这个时候我们仅仅只需要查找2次就可以查找到39,但是相对的维护这么一个结构也增加了内存空间的消耗。
skiplist
从上面我们就可以得知,skiplist实际就是一个用空间换时间的数据结构,skiplist提取出链表中的关键节点(索引),先在关键节点上面查找,再进入下层链表查找,这样提取出多层的关键节点,最后就形成了跳跃表(skiplist)。
时间复杂度
如果一个链表有N个节点,那么
skiplist里会有多少级索引呢?
按照上面的结构来推算:
- 第一级索引大约有个节点。
- 第二级索引大约有个节点。
- 第三级索引大约有个节点。
依次类推,所以我们可以知道第M级索引将大约有。假设索引的最高级T,只有两个节点(头节点和尾节点),通过这个公式我们可以得知,,所以最后我们可以得知最高级,如果包含原始的链表,那么整个skiplist的高度就是。
所以skiplist的时间复杂度也就是O(log2N)。
空间复杂度
相对于一个普通单向链表,一个
skiplist需要额外存储多级索引,那这些额外的索引需要消耗多少空间呢?
这里还是假设有一个长度为N的单向链表,根据上面我们得知从第一级索引开始每层的节点数分别是:、、…、、,每往上一层,节点就少一半,直到最后只剩下2个节点。就是一个等比数列。那么这些索引的总和也就是,所以我们可以得知skiplist的空间复杂度就是O(N),也就是说如果将包含N个节点的单向链表构造成skiplist,还需要额外再使用接近N个节点的存储空间。
结构设计
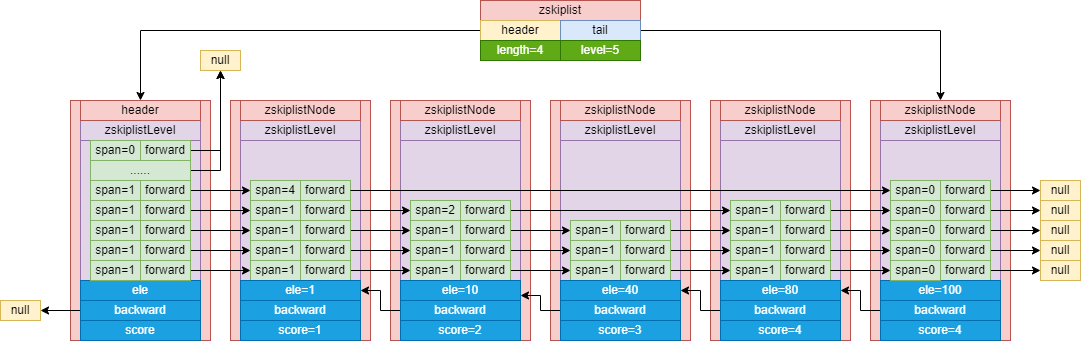
在源码server.h第930行可以看到定义了一个叫zskiplist的结构:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
*header:指向头节点的指针,可以通过这个指针在O(1)的时间复杂度内定位到头节点。*tail:指向尾节点的指针,可以通过这个指针在O(1)的时间复杂度内定位到头节点。length:记录了skiplist的长度,也就是skiplist包含的节点数量(不包括头节点),可以在O(1)的时间复杂度内返回skiplist长度。level:记录了skiplist的最大层数,可以在O(1)的时间复杂度内最大层数。
节点的结构
而skiplist的节点的结构则在源码server.h第920行:
typedef struct zskiplistNode {
/* 成员对象 */
sds ele;
/* 分值 作为索引 */
double score;
/*后退指针,用于从后往前遍历使用 */
struct zskiplistNode *backward;
/* 节点的层结构 数组 */
struct zskiplistLevel {
/* 前指针 */
struct zskiplistNode *forward;
/* 跨度,用来确定本节点再链表中的排位 zrank */
unsigned long span;
} level[];
} zskiplistNode;
-
ele:每个节点保存的成员对象,在同一个skiplist中,每个节点保存的成员对象必须是唯一的,但是多个节点保存的score(分值)却可以是相同的。score(分值)相同的节点将按照成员对象在字典排序中的大小来进行排序,成员对象较小的节点会排在前面,而成员对象较大的节点则会排在后面。 -
score:在skiplist中,每个节点按各自所保存的分值从小到大排列。 -
*backward:指向位于当前层的前一个节点,在从后往前遍历时使用。与前进指针所不同的是每个节点只有一个后退指针,因此每次只能后退一个节点。 -
zskiplistLevel:节点的层结构,每个层结构都有两个属性分别是*forward和span(前进指针和跨度):*forward:用来访问位于表尾方向的其他节点span:记录了*forward(前进指针)所指向节点和当前节点的距离(也就是跨度越大,距离越远)。
结构图
那么在Redis中,skiplist的结构就是这样的: