
Redis淘汰策略
Redis的最大占用内存
如何查看Redis最大占用内存?
在配置文件中可以找到配置项maxmemory <bytes>:
# 设置内存使用限制为指定的字节数。
# 当达到内存限制时,Redis将根据所选的淘汰策略尝试删除键。
#
# 如果Redis无法根据策略删除键,或者策略设置为“noeviction”,Redis将开始
# 对使用更多内存的命令(如SET,LPUSH等)回复错误,并将继续回复只读命令(如GET)。
#
# 当使用Redis作为LRU或LFU缓存,或者设置实例的硬内存限制时,此选项通常很有用(使用“noeviction”策略)。
#
# 警告:如果将副本附加到具有maxmemory的实例,
# 需要用于馈送副本的输出缓冲区的大小会从已使用的内存计数中减去,
# 以便网络问题/重新同步不会触发循环,其中键被清除,
# 反过来,副本的输出缓冲区用DEL清除被清除的键,触发更多键的删除,
# 依此类推,直到完全清空数据库。
#
# 简而言之...如果您有附加的副本,则建议您设置较低的maxmemory限制,
# 以便系统上有一些空闲RAM可供副本输出缓冲区使用
# (但是如果策略是“noeviction”,则不需要这样做)。
#
# maxmemory <bytes>
如果不设置maxmemory或者设置为0(默认就是0),那么在64位操作系统下则不限制内存大小,在32位操作系统下最多能使用3GB的内存。可以使用info memory查看Redis内存使用情况。
Redis是如何删除数据的
Redis过期键的删除策略
如果一个键过期了,那Redis是不是在它过期时马上就从内存中删除它呢?
三种删除策略
立即删除
Redis不可能时时刻刻遍历所有被设置的过期时间的key来检测数据是否已经达到过期时间,然后对它进行删除。立即删除能保证内存中数据的最大新鲜度,因为这样可以保证key在过期后马上被删除,其占用的内存也会随之释放。但是这样对CPU不太友好。因为删除操作会占用CPU的时间,如果刚好碰上了CPU很忙的时候,比如正在做交集或者排序统计的时候,会给CPU造成额外压力,产生大量性能消耗,同时还会影响数据的读取操作。
立即删除对CPU不友好,用CPU性能换内存空间。
惰性删除
数据到达过期时间了,不做处理,等到下一次访问该数据的时候,如果没有过期则返回数据,如果发现过期了,则删除数据并返回数据不存在。这样做的缺点就是对内存不友好。如果一个key已经过期了,但是它实际还保存在Redis的内存中,其占用的内存不会释放,比如Redis中有大量的过期键,而这些过期键有恰好没有被访问到的话,那么这些key也许永远也不会被删除(除非手动删除),这种情况甚至可以看作内存泄漏(一堆垃圾数据占用大量内存),服务器又不会主动去释放它们,这样对于依赖内存的Redis来说肯定是不好的。可以使用lazyfree-lazy-eviction yes开启惰性删除。
惰性删除对内存不友好,用内存空间换CPU性能。
定期删除
定期删除则是上面两种策略的折中,定期删除就是每隔一段时间执行一次删除过期键的操作并通过限制删除操作执行时长和频率来减少删除键对CPU的影响。
周期性轮询Redis库中的时效性,采用随机抽取的策略,利用过期数据占比的方式控制删除频度:
- 特点1:CPU性能占用设置有峰值,检测频度可自定义设置。
- 特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理。
比如Redis默认每隔100ms就检查是否有过期的key,有的话就删除(🚨注意这里Redis并不是每隔100ms就将所有key检查一次而是随机地抽取来检查)。因此如果只是采用这种策略地话会导致很多key不会被删除。
定期删除策略地难点就是确定删除操作执行地时长和频率:
- 如果删除操作执行的次数太多或者执行的时间太长,那么就会和立即删除的缺点一样了。
- 如果删除操作执行的次数太少或者执行的时间太短,那么就会和惰性删除的缺点一样了。
所以如果要使用惰性删除的话,服务器必须根据使用情况,合理地设置删除操作的执行时长和频率。
定期删除是一个折中的方法,但是也会存在漏网之鱼。
淘汰策略
上面说到了三种删除策略,都存在一定的缺陷,那么Redis有更好的方案吗?
淘汰策略有哪些
在Redis中一共有8种淘汰策略,默认的是
noeviction(不删除任何数据)。
可以从两个维度(过期键中筛选或所有键中筛选)以及四个算法(LRU、LFU、Random、ttl)来区分其余7个淘汰策略。
| LRU | LFU | Random | TTL | |
|---|---|---|---|---|
| 过期键中筛选 | volatile-lru | volatile-lfu | volatile-random | volatile-ttl |
| 所有键中筛选 | allkeys-lru | allkeys-lfu | allkeys-random |
淘汰策略的作用分别是什么
在Redis配置文件中是这样描述淘汰策略的:
# MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
# is reached. You can select one from the following behaviors:
#
# volatile-lru -> Evict using approximated LRU, only keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU, only keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key having an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
#
# LRU means Least Recently Used
# LFU means Least Frequently Used
#
# Both LRU, LFU and volatile-ttl are implemented using approximated
# randomized algorithms.
#
# Note: with any of the above policies, when there are no suitable keys for
# eviction, Redis will return an error on write operations that require
# more memory. These are usually commands that create new keys, add data or
# modify existing keys. A few examples are: SET, INCR, HSET, LPUSH, SUNIONSTORE,
# SORT (due to the STORE argument), and EXEC (if the transaction includes any
# command that requires memory).
#
# The default is:
#
# maxmemory-policy noeviction
MAXMEMORY策略:当达到maxmemory时,Redis将选择怎么删除键。可以从以下行为中选择一个:
noeviction:默认策略,不淘汰数据;大部分写命令都将返回错误(DEL等少数除外)。allkeys-lru:从所有数据中根据LRU算法挑选数据淘汰。volatile-lru:从设置了过期时间的数据中根据LRU算法挑选数据淘汰。allkeys-random:从所有数据中随机挑选数据淘汰。volatile-random:从设置了过期时间的数据中随机挑选数据淘汰。volatile-ttl:移除剩余时间最短(TTL最小)的键。allkeys-lfu:从所有数据中根据LFU算法挑选数据淘汰(4.0及以上版本可用)。volatile-lfu:从设置了过期时间的数据中根据LFU算法挑选数据淘汰(4.0及以上版本可用)。
LRU(Least Recently Used)表示最近最少使用,LFU(Least Frequently Used)表示最少使用频率。LRU、LFU和volatile-ttl都使用近似随机算法实现。
注意:使用上述任何策略时,当没有适当的键可用于淘汰时,Redis将对需要更多内存的写操作返回错误。这些通常是创建新键、添加数据或修改现有键的命令。一些示例包括:SET、INCR、HSET、LPUSH、SUNIONSTORE、SORT(由于SCORE参数)和EXEC(如果事务包含任何需要内存的命令)。
怎样选择使用哪种淘汰策略
- 在所有key都是最近经常使用的情况,那么就选择
allkeys-lru,如果不确定使用哪种策略的话,推荐使用allkeys-lru。 - 如果所有key的访问频率都是差不多的,那么可以选择
allkeys-random策略。 - 如果对数据有足够的了解,能够为key指定hint(通过expire/ttl指定),那么可以选择
volatile-ttl。
LRU以及LFU算法
LRU算法
原生的LRU算法
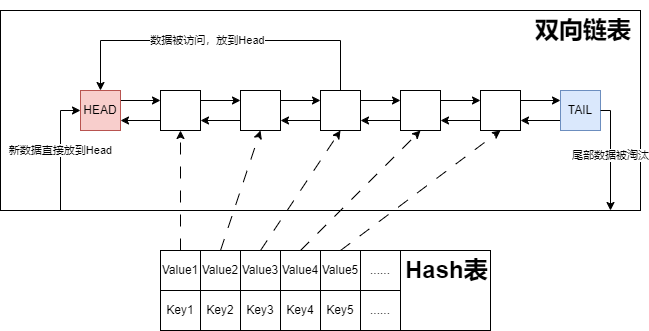
LRU(Least Recently Used)最近最少使用。优先淘汰最近未被使用的数据,其核心思想是:如果数据最近被访问过,那么将来被访问的几率也更高。LRU底层结构是hash表+双向链表。hash表用于保证查询操作的时间复杂度是O(1),双向链表用于保证节点插入和节点删除的时间复杂度是O(1)。
为什么是双向链表而不是单链表呢?单链表可以实现头部插入新节点、尾部删除旧节点的时间复杂度都是O(1),但是对于中间节点时间复杂度是O(n),因为对于中间节点c,我们需要将该节点c移动到头部,此时只知道他的下一个节点,要知道其上一个节点需要遍历整个链表,时间复杂度为O(n)。
- LRU GET操作:如果节点存在,则将该节点移动到链表头部,并返回节点值。
- LRU PUT操作:
- 节点不存在,则新增节点,并将该节点放到链表头部。
- 节点存在,则更新节点,并将该节点放到链表头部。
Redis的近似LRU算法
Redis为什么不使用原生的LRU算法呢?
Redis不使用原生LRU算法的主要原因有:
- 原生LRU算法需要双向链表来管理数据,需要额外内存。
- 数据访问时涉及数据移动,有性能损耗。
- Redis现有数据结构需要改造。
Redis使用LRU算法来淘汰过期的缓存数据,以保持内存的整洁和高效。但是LRU算法的实现需要耗费大量的时间和空间,因为它需要跟踪每个缓存数据最后一次被访问的时间戳。为了解决这个问题,Redis使用了一种近似LRU算法,它通过一些简单的逻辑来实现近似LRU算法的效果,同时减少了空间和时间的开销。
Redis的近似LRU算法逻辑
-
第一次淘汰:随机抽取
maxmemory-samples(在配置文件中修改,默认为5)个数据放入待淘汰数据池(evictionPoolEntry)。修改
maxmemory-samples配置为10的话将非常接近原生LRU效果,但是更消耗CPU。可以参考官方的说明。
-
第二次淘汰:还是随机抽取
maxmemory-samples个数据,但是只要数据比待淘汰数据池(evictionPoolEntry)中的任意一个数据的lru小,则将该数据放入至待淘汰数据池。 -
执行淘汰:挑选待淘汰数据池中lru最小的一条数据进行淘汰。
Redis的近似LRU算法的缺陷
假设现在又三个key分别是A、B、C,在一段时间T内A被访问了6次,B被访问了4次,C被访问了2次,如下所示,从左往右表示时间,|表示开始和结束、-表示一个单位的时间。
|----A----A----A----A-----A---A-------------|
|-----B--------B----B----------------B------|
|-------------------C---------------------C-|
当系统内存达到限制,触发LRU算法的时候,开始淘汰key的时候,如果按照LRU算法的逻辑(最近最少使用),那么被淘汰的概率将是A>B>C。然而实际上A的访问次数却是最多的,当我们并不希望A被淘汰,而是希望淘汰的概率是C>B>A的时候,使用LRU算法显然不太合适。淘汰算法的本意是保留那些将来最有可能被再次访问的数据,而LRU算法只是预测最近被访问的数据将来最有可能被访问到。所以在Redis4.0的时候推出了LFU算法(Least Frequently Used)。
LFU算法
LFU(Least Frequently Used)是Redis4.0引入的淘汰算法,它通过key的访问频率、访问时间比较来淘汰key,重点突出的是Frequently Used。
因为LFU算法是根据数据访问的频率来选择被淘汰数据的,所以LFU算法会记录每个数据的访问次数。当一个数据被再次访问时,就会增加该数据的访问次数。但是,访问次数和访问频率这两者并不完全相同。访问频率是指在一定时间内的访问次数。比如现在有两个key分别是A、B。A在15min内被访问了60次,B在5min内被访问了30次。如果是看访问次数的话,毫无疑问A肯定大于B,但是如果是计算访问频率的话,A被访问的频率则是4次/min,而B则是6次/min。所以B的访问频率是肯定大于A的。先被淘汰的key应该是A而不是B。
LFU算法的实现逻辑
在LFU算法中,为每个key维护一个计数器。每次key被访问的时候,计数器增大。计数器越大,可以说明访问越频繁。但是这样做存在一定的问题,上面也说到了访问次数和访问频率并不完全相同。所以只是简单的增加计数器的方法并不完美。访问模式是会频繁变化的,一段时间内频繁访问的key一段时间之后可能会很少被访问到,只增加计数器并不能体现这种趋势。
在Redis中key的对象是redisObject,结构如下:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
源码中的注释也说到了24bits的lru:LRU_BITS是用来记录LRU time的,然后LFU策略同样可以使用这个字段,但是是分为16bit和8bit来使用,前16bit用来记录最近一次计数器降低的时间Last decr time,单位是分钟,后8bit记录计数器数值counter。
16 bits 8 bits
+----------------+--------+
+ Last decr time | LOG_C |
+----------------+--------+
所以当LFU策略筛选数据时,Redis会在候选集合中,根据lru:LRU_BITS字段的后8bit选择访问次数最少的数据进行淘汰。当访问次数相同时,再根据lru:LRU_BITS字段的前16bit值大小,选择访问时间最久远的数据进行淘汰。可以看到Redis只使用了8bit来记录数据的访问次数,但是8bit记录的最大值是255,当访问量大的时候,如果每次访问都加1,那么很快就会达到最大值255,这时可能大多数数据都是255的访问次数,这样就都会使用前16bit来进行淘汰了,相当于退化成LRU了。但是Redis使用了另外一种计数规则,这个规则还可以使用配置项来控制计数器的增加速度。
# lfu-log-factor 10
# lfu-decay-time 1
-
lfu-log-factor:用计数器counter当前的值乘以配置项lfu-log-factor再加1,再取其倒数,得到一个p值。然后,把这个p值和一个取值范围在(0,1)间的随机数r值比大小,只有当p>r的时候计数器才会加1。也就是lfu-log-factor越大,counter增长的越慢。配置文件中还列举了使用不同的lfu-log-factor时counter增长情况:# +--------+------------+------------+------------+------------+------------+ # | factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits | # +--------+------------+------------+------------+------------+------------+ # | 0 | 104 | 255 | 255 | 255 | 255 | # +--------+------------+------------+------------+------------+------------+ # | 1 | 18 | 49 | 255 | 255 | 255 | # +--------+------------+------------+------------+------------+------------+ # | 10 | 10 | 18 | 142 | 255 | 255 | # +--------+------------+------------+------------+------------+------------+ # | 100 | 8 | 11 | 49 | 143 | 255 | # +--------+------------+------------+------------+------------+------------+可以看到
counter增长与访问次数呈现对数增长的趋势,随着访问次数越来越大,counter增长的越来越慢。 -
lfu-decay-time:用来控制访问次数衰减。LFU策略会计算当前时间和数据最近一次访问时间的差值,并把这个差值换算成以分钟为单位。然后再把这个差值除以lfu-decay-time值,所得的结果就是数据counter要衰减的值。
lfu-log-factor设置越大,递增概率越低,lfu-decay-time设置越大,衰减速度会越慢。
在应用LFU策略时,一般可以将lfu-log-factor设置为10。 如果业务应用中有短时高频访问的数据的话,建议把lfu-decay-time设置为1。可以快速衰减访问次数。
LRU和LFU算法的区别
| 算法 | LRU(Least Recently Used) | LFU(Least Frequently Used) |
|---|---|---|
| 核心思想 | 按照最近使用时间淘汰 | 按照使用频率淘汰 |
| 淘汰策略 | 淘汰最久未被使用的数据 | 淘汰使用频率最低的数据 |
| 适用场景 | 数据访问具有时间局部性的场景 | 数据访问具有空间局部性的场景 |
总体来说,LRU算法适合用于数据访问具有时间局部性的场景,即最近访问的数据在不久的将来可能再次被访问,而LFU算法适合用于数据访问具有空间局部性的场景,即访问频率高的数据在不久的将来仍然会被频繁访问。