
布隆过滤器BloomFilter
布隆过滤器(Bloom Filter)是在1970年由布隆提出的。Bloom Filter是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
False Positive:中文可以理解为“假阳性”,在这里表示,有可能把不属于这个集合的元素误认为属于这个集合False Negative:中文可以理解为“假阴性”,Bloom Filter是不存在False Negatived的, 即不会把属于这个集合的元素误认为不属于这个集合(False Negative)。
通常遇到很多需要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较来确定。链表、树、哈希表等等数据结构都是这种思路。但是随着集合中的元素增加,需要的存储空间也会线性增长,最终达到瓶颈。同时检索速度也会越来越慢,上述三种数据结构检索的时间复杂度分别是O(N)、O(logn)、O(1)。这时,布隆过滤器也就诞生了。布隆过滤器时一种类似于Set的数据结构,只是统计结果在巨量数据下有点小瑕疵,不够完美。
简单说就是一个元素的判断结果如果是:
- 存在:这个元素不一定存在(可能)。
- 不存在:这个元素一定不存在。
布隆过滤器可以添加元素,但是最好不要删除元素,因为涉及hashcode判断依据,删掉元素会导致误判率增加。
布隆过滤器的原理
假设我们想要比较两个字符串。我们不存储整个字符串,而是计算字符串的哈希值,然后比较哈希值。计算哈希值然后比较它们只需要O(1)的时间,而不是直接比较字符串所需的O(n)时间。如果两个哈希值不相等,我们可以确定字符串不相等。否则,两个字符串可能是相等的!
这种方法的一个缺点是哈希函数的范围有限。哈希函数h1的范围是0到r1-1。我们无法使用这种方法唯一地识别超过r1个字符串,因为至少两个字符串将具有相同的哈希值。为了弥补这一点,我们可以使用多个哈希函数。
假设我们使用k个哈希函数h1,h2,…,hk,将两个字符串通过这些哈希函数传递,并计算它们的哈希值。如果两个字符串的所有哈希值都相同,则非常有可能两个字符串相同。另一方面,即使一个哈希值不匹配,我们也可以说这两个字符串是不同的。
Bloom过滤器是一种存储0和1的数组。在下面的图片中,每个单元格代表一个位。位下面的数字是大小为10的Bloom过滤器的索引。
向布隆过滤器插入数据
为了添加1个元素,需要通过k个哈希函数进行计算。例如想要添加单词Java。经过3个哈希函数后,得到以下结果:
hash1("Java") = 125hash2("Java") = 67hash3("Java") = 19
假设布隆过滤器的大小为m=10。则需要对上面计算出来的每个值对10取模,以便索引落在布隆过滤器的范围内。因此,计算完之后,索引为125%10 = 5,67%10 = 7和19%10 = 9的位置必须设置为1。
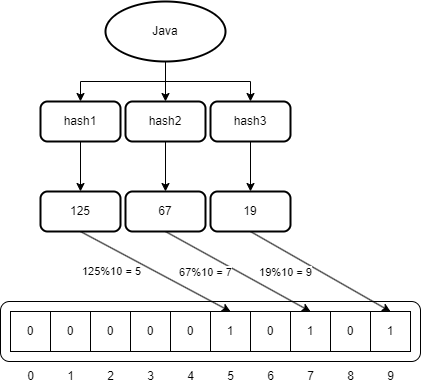
如上图所示Java在3个哈希函数计算后结果分别125、67、19,然后对10取模获取在布隆过滤器上的索引,然后将布隆过滤器上索引对应的值设置为1,这样对完成了添加元素到布隆过滤器。
查询布隆过滤器(判断是否存在)
如果想测试1个元素是否存在于布隆过滤器,那么需要将它通过相同的哈希函数计算。
- 如果所有这些索引对应的值都已经被设置成了1,那么这个元素可能存在。
- 只要有1个索引没有被设置,那么就可以确定这个元素不存在。
这里假设我们想要检查C++是否存在。在这之前,已经向布隆过滤器中添加了两个元素Java和GO。
Java通过3个哈希函数的计算结果为{125,67,19},并且如上所述,索引{5,7,9}对应的值设置为1。Go通过3个哈希函数的计算结果为{290,145,2},索引{0,2,5}设置为1。
最后数组状态如下:
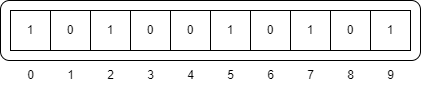
-
通过相同的哈希函数对
C++进行处理,得到以下结果:hash1("C++") = 233hash2("C++") = 155hash3("C++") = 9
然后检查索引
{3,5,9}是否都已经被设置为1。通过上图可以看到,即使索引5和9被设置为1,但是索引3的值还是0。因此,我们可以百分之百地得出结论,C++不存在。 -
再次假设想要检查
python是否存在。通过同样的哈希函数进行处理,得到以下结果:hash1("python") = 235hash2("python") = 60hash3("python") = 22
检查索引
{0, 2, 5}是否都设置为1。可以看到这些索引都被设置为1。然而,实际上python并不存在。因此,这是一个误报。
误报率
那能预测这些误报的概率吗?能,下面将说明。
设n=元素数量,m=布隆过滤器长度,k=哈希函数数量。假设哈希函数计算后得到的索引值落在数组上每一位的概率是相同的,那么:
- 对于一个给定的哈希函数,在插入元素时,一个特定的位没有被设置为1的概率是:
- 如果我们通过k个哈希函数将该元素传递,那么在任何哈希函数中,该位不被设置为1的概率为:
- 插入n个元素后,特定位仍为0的概率为:
- 因此,如果插入n个元素之后,这个位是1的概率是:
- 它们全部为1的概率,即误报的概率是:
如上所述,如果m趋向于无穷大,误报率趋向于零。避免高误报率的另一种方法是使用多个哈希函数。
实现一个布隆过滤器
这里结合Redis的bitmap类型来实现。
package com.error.bloomfilter.utils;
import jakarta.annotation.Resource;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.util.StringUtils;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
* 布隆过滤器实现
*
* @author Error
* @class BloomFilter
*/
public class BloomFilter {
private RedisTemplate<String,Object> redisTemplate;
/* 布隆过滤器长度 */
private final Integer bloomFilterSize;
/* 布隆过滤器默认初始长度分配2^24*/
private static final Integer DEFAULT_SIZE = 2 << 24;
/* 不同哈希函数的种子,一般应取质数 */
private final List<Integer> seeds;
/* 默认哈希函数数量 */
private static final int DEFAULT_HASH_NUM = 8;
public BloomFilter(int bloomFilterSize, Integer hashNum) {
this.bloomFilterSize = bloomFilterSize;
this.seeds = getPrimes(hashNum);
}
public BloomFilter() {
this.bloomFilterSize = DEFAULT_SIZE;
this.seeds = getPrimes(DEFAULT_HASH_NUM);
}
/**
* 根据给定的字符串生成整数作为哈希函数的种子
* @param value
* value
* @return {@link List<Integer>}
* @author Error
*/
private List<Integer> getHashes(String value) {
return seeds.stream()
.map(seed -> hash(value, seed))
.collect(Collectors.toList());
}
/**
* 哈希函数,使用简单的加权和算法
* @param value
* value
* @param seed
* seed
* @return {@link int}
* @author Error
*/
private int hash(String value, int seed) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (bloomFilterSize-1) & result;
}
/**
* 添加元素
* @param value
* value
* @author Error
*/
public void add(String value) {
getHashes(value)
.forEach(hash -> redisTemplate.opsForValue().setBit("bloom_filter", hash, true));
}
/**
* 判断是否可能包含给定的元素
* @param value
* value
* @return {@link boolean}
* @author Error
*/
public boolean exists(String value) {
if(StringUtils.hasText(value)) {
for (Integer hash:getHashes(value)) {
if (Boolean.FALSE.equals(redisTemplate.opsForValue().getBit("bloom_filter", hash))) {
return false;
}
}
return true;
}
return false;
}
/**
* 获取指定数量的质数
* @param count
* 需要获取的质数的数量
* @return {@link List<Integer>}
* @author Error
*/
public List<Integer> getPrimes(Integer count) {
List<Integer> primesList = new ArrayList<>(count);
int num = 2;
while(primesList.size()< count) {
boolean isPrime = true;
for(int i = 2; i <= Math.sqrt(num); i++) {
if(num % i == 0) {
isPrime = false;
break;
}
}
if(isPrime) {
primesList.add(num);
}
num++;
}
return primesList;
}
}